

【本文来自持牌证券机构,不代表平台观点,请独立判断和决策】
【本文来自持牌证券机构,不代表平台观点,请独立判断和决策】
申万宏源指出,9月9日英伟达宣布推出Rubin CPX GPU和Vera Rubin NVL144 CPX平台,Rubin CPX预计于2026年底上线。Rubin CPX是专为长上下文推理和视频生成应用设计的GPU,配备128GB GDDR7,NVFP4优化算力达30PFLOPS,尤其适合百万级tokens的推理场景。
正如Nvidia宣称,Vera Rubin NVL144 CPX平台下,每1亿美元的资本开支可以带来50亿美元token收益。坚定看好AI Infra建设对整个算力产业链的拉动。
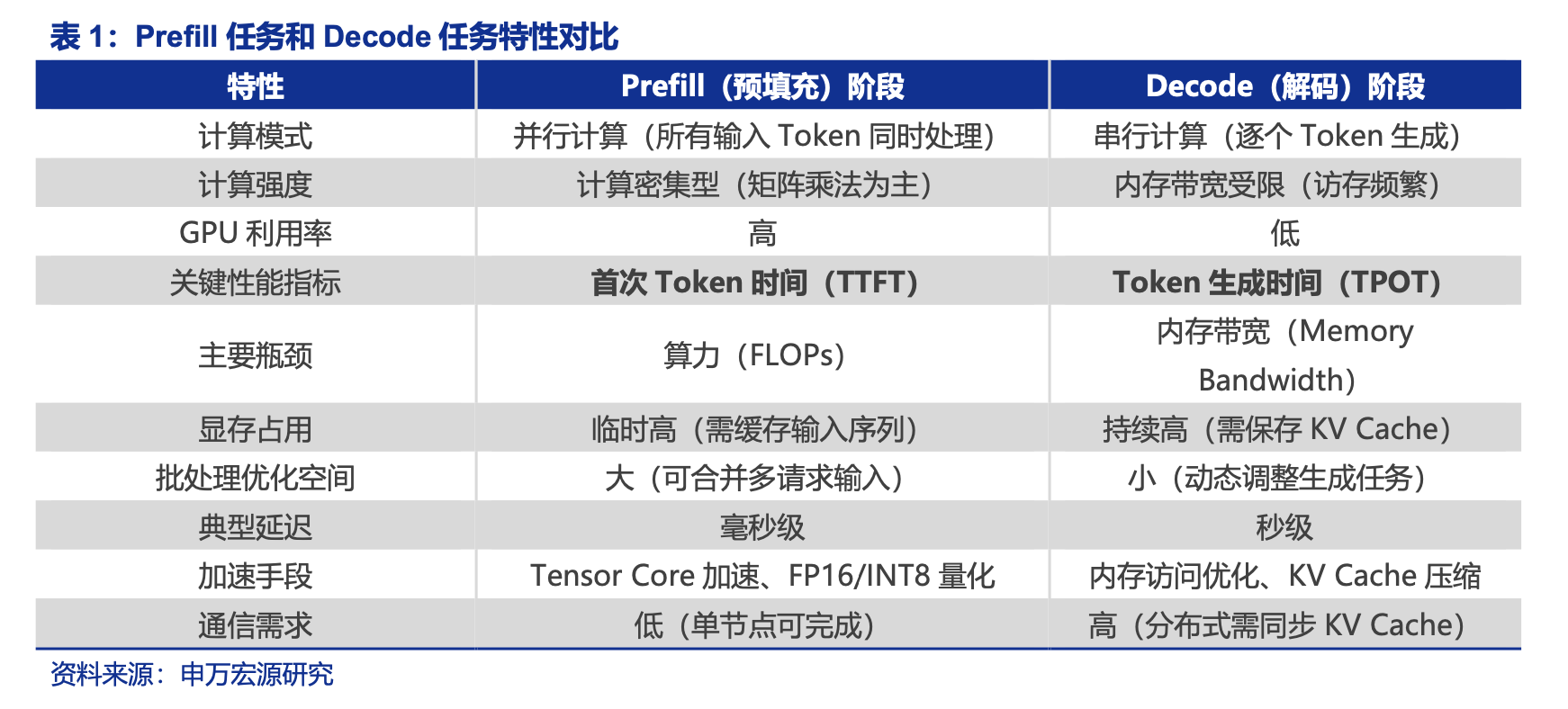
1)Rubin CPX专为计算密集的Prefill阶段优化,BOM成本或低至Rubin的1/4
英伟达发布Rubin CPX,专门针对AI视频生成和软件开发等大规模上下文处理任务。根据SemiAnalysis预测,Rubin CPX将以单光罩尺寸提供20PFLOPS的NVFP4稠密算力(Rubin双光罩尺寸,33PFLOPS),128GB GDDR7(Rubin 288GB HBM4);可集成到VR200Oberon NVL144中,也可作为独立机柜Scale-out至AI集群中运行,为终端客户优化TCO。CPX定于2026年底上市。

2)CPX实质性降低Prefill阶段的首token输出及KV Cache生成成本
PD分离机制是将AI推理过程分为两个独立阶段的系统设计。Prefill(预填充)专注高吞吐计算以处理大量输入数据,Decode(解码)则依赖高速内存传输逐token输出。基于工程优化降本思路,可以将Prefill、Decode阶段分离至不同硬件节点实现。Prefill节点可以增加算力并减少存力,Decode节点可以减少算力并增加存力。
3)Token经济性提升至少来自4个因素
①提高计算效率,针对NVFP4格式优化。该项性能提升可能源自将die面积资源专门用于增加NVFP4计算单元数量。
②GDDR取代HBM,每GB成本相较HBM可降低50%。
③CPX预计将采用成熟的FCBGA单die封装,规避CoWoS带来的成本上升和良率损失。
④CPX无须NVLinkScale-up,而是基于PCIe6.0,通过CX-9进行Scale-out,可节约8,000美元/GPU的扩展成本。

4)算力密度、集成复杂度提升,驱动互联、液冷、组装增量
VR200CPX新增8个CPX,托盘内以硅含量计的算力密度明显提升。相应的,功能单元排布、连接(铜缆/PCB变化)、带宽(网卡数量)、供电及散热均相应变化。
变化①:新增PCB正交中板。
来自HPM母板的PCIe信号通过连接器进入PCB正交中板,再通过另一侧连接器传输到子板上的CX-9NIC和Rubin CPX。通过升级正交中板及子板的CCL材料,可以确保良好的信号完整性。
变化②:CX网卡至OSFP端口的Overpass线缆得以取消。
在VR200计算托盘的新排布中,CX-9网卡从托盘后部移至前部,与OSFP端口的距离得以缩短,传输路径损耗降低,得以通过PCB连接。Overpass线缆取消,提高可维护性并减少空间占用。
变化③:托盘内功率密度提升,液冷用量提升。
预计Rubin CPX和CX-9网卡从托盘后部移至前部的另一潜在原因系为均衡热源分布。为冷却托盘前部的合计TDP达到7040W的8块CPX,散热方式也须从风冷升级为液冷。上下两个CPXPCB将共享一块液冷板,通过充分利用1U托盘高度及冷板双面空间,实现最大的计算资源密度。
关注:
PCB/CCL增量:胜宏科技、方正科技、鹏鼎控股、景旺电子、沪电股份,生益科技,菲利华、中材科技、宏和科技,东材科技。
连接器增量:立讯精密;
集成复杂度提升:工业富联;
液冷用量提升:英维克、领益智造、比亚迪电子。
研报来源:申万宏源,杨海晏,A0230518070003,AI算力行业跟踪点评:英伟达Rubin CPX,TCO与算力密度再进一步,揭示PCB/液冷/组装增量。2025年09月14日
*免责声明:文章内容仅供参考,不构成投资建议
*风险提示:股市有风险,入市需谨慎




